Supporting early career researchers in their open science journey is critical for …
Supporting early career researchers in their open science journey is critical for the future of the field. The development of open science behaviors, however, often requires guidance from faculty and colleagues. This webinar will provide practical and concrete steps for early career researchers to follow to advance their open scholarship practice. Additionally, it will offer tips about how to mentor early career researchers in the development of open science behaviors that will last throughout their careers.
If you are an early career research learning to advance your open science practices or a mentor supporting an early career research, view this informative webinar.
This list of resources consists of resources for researchers, editors, and reviewers …
This list of resources consists of resources for researchers, editors, and reviewers interested in practicing open science principles, particularly in education research. This list is not exhaustive but meant as a starting point for individuals wanting to learn more about doing open science work specifically for qualitative research. For more general information about open science research, please visit https://www.cos.io/.
"Harry Potter and the Methods of Reproducibility -- A brief Introduction to …
"Harry Potter and the Methods of Reproducibility -- A brief Introduction to Open Science" gives a brief overview of Open Science, particularly reproducibility, for newcomers to the topic. It introduces the concept of questionable research practices (QRPs) and Open Science solutions to these QRPs, such as preregistrations, registered reports, Open Data, Open Code, and Open Materials.
Much of the work done by faculty at both public and private …
Much of the work done by faculty at both public and private universities has significant public dimensions: it is often paid for by public funds; it is often aimed at serving the public good; and it is often subject to public evaluation. To understand how the public dimensions of faculty work are valued, we analyzed review, promotion, and tenure documents from a representative sample of 129 universities in the US and Canada. Terms and concepts related to public and community are mentioned in a large portion of documents, but mostly in ways that relate to service, which is an undervalued aspect of academic careers. Moreover, the documents make significant mention of traditional research outputs and citation-based metrics: however, such outputs and metrics reward faculty work targeted to academics, and often disregard the public dimensions. Institutions that seek to embody their public mission could therefore work towards changing how faculty work is assessed and incentivized.
This webinar outlines how to use the free Open Science Framework (OSF) …
This webinar outlines how to use the free Open Science Framework (OSF) as an Electronic Lab Notebook for personal work or private collaborations. Fundamental features we cover include how to record daily activity, how to store images or arbitrary data files, how to invite collaborators, how to view old versions of files, and how to connect all this usage to more complex structures that support the full work of a lab across multiple projects and experiments.
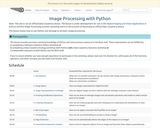
This lesson shows how to use Python and skimage to do basic …
This lesson shows how to use Python and skimage to do basic image processing. With support from an NSF iUSE grant, Dr. Tessa Durham Brooks and Dr. Mark Meysenburg at Doane College, Nebraska, USA have developed a curriculum for teaching image processing in Python. This lesson is currently being piloted at different institutions. This pilot phase will be followed by a clean-up phase to incorporate suggestions and feedback from the pilots into the lessons and to make the lessons teachable by the broader community. Development for these lessons has been supported by a grant from the Sloan Foundation.
Limiting the debilitating consequences of ageing is a major medical challenge of …
Limiting the debilitating consequences of ageing is a major medical challenge of our time. Robust pharmacological interventions that promote healthy ageing across diverse genetic backgrounds may engage conserved longevity pathways. Here we report results from the Caenorhabditis Intervention Testing Program in assessing longevity variation across 22 Caenorhabditis strains spanning 3 species, using multiple replicates collected across three independent laboratories. Reproducibility between test sites is high, whereas individual trial reproducibility is relatively low. Of ten pro-longevity chemicals tested, six significantly extend lifespan in at least one strain. Three reported dietary restriction mimetics are mainly effective across C. elegans strains, indicating species and strain-specific responses. In contrast, the amyloid dye ThioflavinT is both potent and robust across the strains. Our results highlight promising pharmacological leads and demonstrate the importance of assessing lifespans of discrete cohorts across repeat studies to capture biological variation in the search for reproducible ageing interventions.
Despite the potential benefits of sequential designs, studies evaluating treatments or experimental …
Despite the potential benefits of sequential designs, studies evaluating treatments or experimental manipulations in preclinical experimental biomedicine almost exclusively use classical block designs. Our aim with this article is to bring the existing methodology of group sequential designs to the attention of researchers in the preclinical field and to clearly illustrate its potential utility. Group sequential designs can offer higher efficiency than traditional methods and are increasingly used in clinical trials. Using simulation of data, we demonstrate that group sequential designs have the potential to improve the efficiency of experimental studies, even when sample sizes are very small, as is currently prevalent in preclinical experimental biomedicine. When simulating data with a large effect size of d = 1 and a sample size of n = 18 per group, sequential frequentist analysis consumes in the long run only around 80% of the planned number of experimental units. In larger trials (n = 36 per group), additional stopping rules for futility lead to the saving of resources of up to 30% compared to block designs. We argue that these savings should be invested to increase sample sizes and hence power, since the currently underpowered experiments in preclinical biomedicine are a major threat to the value and predictiveness in this research domain.
The last ten years have witnessed increasing awareness of questionable research practices …
The last ten years have witnessed increasing awareness of questionable research practices (QRPs) in the life sciences, including p-hacking, HARKing, lack of replication, publication bias, low statistical power and lack of data sharing (see Figure 1). Concerns about such behaviours have been raised repeatedly for over half a century but the incentive structure of academia has not changed to address them. Despite the complex motivations that drive academia, many QRPs stem from the simple fact that the incentives which offer success to individual scientists conflict with what is best for science. On the one hand are a set of gold standards that centuries of the scientific method have proven to be crucial for discovery: rigour, reproducibility, and transparency. On the other hand are a set of opposing principles born out of the academic career model: the drive to produce novel and striking results, the importance of confirming prior expectations, and the need to protect research interests from competitors. Within a culture that pressures scientists to produce rather than discover, the outcome is a biased and impoverished science in which most published results are either unconfirmed genuine discoveries or unchallenged fallacies. This observation implies no moral judgement of scientists, who are as much victims of this system as they are perpetrators.
Recently, many psychological effects have been surprisingly difficult to reproduce. This article …
Recently, many psychological effects have been surprisingly difficult to reproduce. This article asks why, and investigates whether conceptually replicating an effect in the original publication is related to the success of independent, direct replications. Two prominent accounts of low reproducibility make different predictions in this respect. One account suggests that psychological phenomena are dependent on unknown contexts that are not reproduced in independent replication attempts. By this account, internal replications indicate that a finding is more robust and, thus, that it is easier to independently replicate it. An alternative account suggests that researchers employ questionable research practices (QRPs), which increase false positive rates. By this account, the success of internal replications may just be the result of QRPs and, thus, internal replications are not predictive of independent replication success. The data of a large reproducibility project support the QRP account: replicating an effect in the original publication is not related to independent replication success. Additional analyses reveal that internally replicated and internally unreplicated effects are not very different in terms of variables associated with replication success. Moreover, social psychological effects in particular appear to lack any benefit from internal replications. Overall, these results indicate that, in this dataset at least, the influence of QRPs is at the heart of failures to replicate psychological findings, especially in social psychology. Variable, unknown contexts appear to play only a relatively minor role. I recommend practical solutions for how QRPs can be avoided.
Workshop goals - Why are we teaching this - Why is this …
Workshop goals - Why are we teaching this - Why is this important - For future and current you - For research as a whole - Lack of reproducibility in research is a real problem
Materials and how we'll use them - Workshop landing page, with
- links to the Materials - schedule
Structure oriented along the Four Facets of Reproducibility:
How this workshop is run - This is a Carpentries Workshop - that means friendly learning environment - Code of Conduct - active learning - work with the people next to you - ask for help
Data Carpentry lesson to learn how to work with Amazon AWS cloud …
Data Carpentry lesson to learn how to work with Amazon AWS cloud computing and how to transfer data between your local computer and cloud resources. The cloud is a fancy name for the huge network of computers that host your favorite websites, stream movies, and shop online, but you can also harness all of that computing power for running analyses that would take days, weeks or even years on your local computer. In this lesson, you’ll learn about renting cloud services that fit your analytic needs, and how to interact with one of those services (AWS) via the command line.
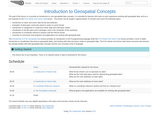
Data Carpentry lesson to understand data structures and common storage and transfer …
Data Carpentry lesson to understand data structures and common storage and transfer formats for spatial data. The goal of this lesson is to provide an introduction to core geospatial data concepts. It is intended for learners who have no prior experience working with geospatial data, and as a pre-requisite for the R for Raster and Vector Data lesson . This lesson can be taught in approximately 75 minutes and covers the following topics: Introduction to raster and vector data format and attributes Examples of data types commonly stored in raster vs vector format Introduction to categorical vs continuous raster data and multi-layer rasters Introduction to the file types and R packages used in the remainder of this workshop Introduction to coordinate reference systems and the PROJ4 format Overview of commonly used programs and applications for working with geospatial data The Introduction to R for Geospatial Data lesson provides an introduction to the R programming language while the R for Raster and Vector Data lesson provides a more in-depth introduction to visualization (focusing on geospatial data), and working with data structures unique to geospatial data. The R for Raster and Vector Data lesson assumes that learners are already familiar with both geospatial data concepts and the core concepts of the R language.
Data Carpentry lesson to open, work with, and plot vector and raster-format …
Data Carpentry lesson to open, work with, and plot vector and raster-format spatial data in R. The episodes in this lesson cover how to open, work with, and plot vector and raster-format spatial data in R. Additional topics include working with spatial metadata (extent and coordinate reference systems), reprojecting spatial data, and working with raster time series data.
This workshop introduces the basic concepts of Git version control. Whether you're …
This workshop introduces the basic concepts of Git version control. Whether you're new to version control or just need an explanation of Git and GitHub, this two hour tutorial will help you understand the concepts of distributed version control. Get to know basic Git concepts and GitHub workflows through step-by-step lessons. We'll even rewrite a bit of history, and touch on how to undo (almost) anything with Git. This is a class for users who are comfortable with a command-line interface.
This class is designed for first-time and longer-term users of Jupyter Notebooks, …
This class is designed for first-time and longer-term users of Jupyter Notebooks, a workspace for writing code. The class focuses on using Notebooks to facilitate sharing and publishing of script workflows. It aims to provide users with knowledge about shortcuts, plugins, and best practices for maximizing re-usability and shareability of Notebook contents.
This is a recording of a 45 minute introductory webinar on preprints. …
This is a recording of a 45 minute introductory webinar on preprints. With our guest speaker Philip Cohen, we’ll cover what preprints/postprints are, the benefits of preprints, and address some common concerns researcher may have. We’ll show how to determine whether you can post preprints/postprints, and also demonstrate how to use OSF preprints (https://osf.io/preprints/) to share preprints. The OSF is the flagship product of the Center for Open Science, a non-profit technology start-up dedicated to improving the alignment between scientific values and scientific practices. Learn more at cos.io and osf.io, or email contact@cos.io.
In this webinar, Doctors David Mellor (Center for Open Science) and Stavroula …
In this webinar, Doctors David Mellor (Center for Open Science) and Stavroula Kousta (Nature Human Behavior) discuss the Registered Reports publishing workflow and the benefits it may bring to funders of research. Dr. Mellor details the workflow and what it is intended to do, and Dr. Kousta discusses the lessons learned at Nature Human Behavior from their efforts to implement Registered Reports as a journal.
No restrictions on your remixing, redistributing, or making derivative works. Give credit to the author, as required.
Your remixing, redistributing, or making derivatives works comes with some restrictions, including how it is shared.
Your redistributing comes with some restrictions. Do not remix or make derivative works.
Most restrictive license type. Prohibits most uses, sharing, and any changes.
Copyrighted materials, available under Fair Use and the TEACH Act for US-based educators, or other custom arrangements. Go to the resource provider to see their individual restrictions.