The goal of this lesson is to provide an introduction to R …
The goal of this lesson is to provide an introduction to R for learners working with geospatial data. It is intended as a pre-requisite for the R for Raster and Vector Data lesson for learners who have no prior experience using R. This lesson can be taught in approximately 4 hours and covers the following topics: Working with R in the RStudio GUI Project management and file organization Importing data into R Introduction to R’s core data types and data structures Manipulation of data frames (tabular data) in R Introduction to visualization Writing data to a file The the R for Raster and Vector Data lesson provides a more in-depth introduction to visualization (focusing on geospatial data), and working with data structures unique to geospatial data.
Command line interface (OS shell) and graphic user interface (GUI) are different …
Command line interface (OS shell) and graphic user interface (GUI) are different ways of interacting with a computer’s operating system. The shell is a program that presents a command line interface which allows you to control your computer using commands entered with a keyboard instead of controlling graphical user interfaces (GUIs) with a mouse/keyboard combination. There are quite a few reasons to start learning about the shell: The shell gives you power. The command line gives you the power to do your work more efficiently and more quickly. When you need to do things tens to hundreds of times, knowing how to use the shell is transformative. To use remote computers or cloud computing, you need to use the shell.
Data Carpentry lesson to learn to navigate your file system, create, copy, …
Data Carpentry lesson to learn to navigate your file system, create, copy, move, and remove files and directories, and automate repetitive tasks using scripts and wildcards with genomics data. Command line interface (OS shell) and graphic user interface (GUI) are different ways of interacting with a computer’s operating system. The shell is a program that presents a command line interface which allows you to control your computer using commands entered with a keyboard instead of controlling graphical user interfaces (GUIs) with a mouse/keyboard combination. There are quite a few reasons to start learning about the shell: For most bioinformatics tools, you have to use the shell. There is no graphical interface. If you want to work in metagenomics or genomics you’re going to need to use the shell. The shell gives you power. The command line gives you the power to do your work more efficiently and more quickly. When you need to do things tens to hundreds of times, knowing how to use the shell is transformative. To use remote computers or cloud computing, you need to use the shell.
This video will introduce how to calculate confidence intervals around effect sizes …
This video will introduce how to calculate confidence intervals around effect sizes using the MBESS package in R. All materials shown in the video, as well as content from our other videos, can be found here: https://osf.io/7gqsi/
Welcome to R! Working with a programming language (especially if it’s your …
Welcome to R! Working with a programming language (especially if it’s your first time) often feels intimidating, but the rewards outweigh any frustrations. An important secret of coding is that even experienced programmers find it difficult and frustrating at times – so if even the best feel that way, why let intimidation stop you? Given time and practice* you will soon find it easier and easier to accomplish what you want. Why learn to code? Bioinformatics – like biology – is messy. Different organisms, different systems, different conditions, all behave differently. Experiments at the bench require a variety of approaches – from tested protocols to trial-and-error. Bioinformatics is also an experimental science, otherwise we could use the same software and same parameters for every genome assembly. Learning to code opens up the full possibilities of computing, especially given that most bioinformatics tools exist only at the command line. Think of it this way: if you could only do molecular biology using a kit, you could probably accomplish a fair amount. However, if you don’t understand the biochemistry of the kit, how would you troubleshoot? How would you do experiments for which there are no kits? R is one of the most widely-used and powerful programming languages in bioinformatics. R especially shines where a variety of statistical tools are required (e.g. RNA-Seq, population genomics, etc.) and in the generation of publication-quality graphs and figures. Rather than get into an R vs. Python debate (both are useful), keep in mind that many of the concepts you will learn apply to Python and other programming languages. Finally, we won’t lie; R is not the easiest-to-learn programming language ever created. So, don’t get discouraged! The truth is that even with the modest amount of R we will cover today, you can start using some sophisticated R software packages, and have a general sense of how to interpret an R script. Get through these lessons, and you are on your way to being an accomplished R user! * We very intentionally used the word practice. One of the other “secrets” of programming is that you can only learn so much by reading about it. Do the exercises in class, re-do them on your own, and then work on your own problems.
Today we are going to learn the basics of literate programming using …
Today we are going to learn the basics of literate programming using Jupyter Notebooks, a popular tool in data science, with the R kernel, so we can run R code in our notebooks. We’ll then take a look at how we use Git and GitHub to keep track of all the versions of our work, collaborate with others, and be open!
Software Carpentry lección para la terminal de Unix La terminal de Unix …
Software Carpentry lección para la terminal de Unix La terminal de Unix ha existido por más tiempo que la mayoría de sus usuarios. Ha sobrevivido tanto tiempo porque es una herramienta poderosa que permite a las personas hacer cosas complejas con sólo unas pocas teclas. Lo más importante es que ayuda a combinar programas existentes de nuevas maneras y automatizar tareas repetitivas, en vez de estar escribiendo las mismas cosas una y otra vez. El uso del terminal o shell es fundamental para usar muchas otras herramientas poderosas y recursos informáticos (incluidos los supercomputadores o “computación de alto rendimiento”). Esta lección te guiará en el camino hacia el uso eficaz de estos recursos.
The book is associated with the lsr package on CRAN and GitHub. …
The book is associated with the lsr package on CRAN and GitHub. The package is probably okay for many introductory teaching purposes, but some care is required. The package does have some limitations (e.g., the etaSquared function does strange things for unbalanced ANOVA designs), and it has not been updated in a while.
Purpose: To introduce methods and tools in organization, documentation, automation, and dissemination …
Purpose: To introduce methods and tools in organization, documentation, automation, and dissemination of research that nudge it further along the reproducibility spectrum.OutcomeParticipants feel more confident applying reproducibility methods and tools to their own research projects.ProcessParticipants practice new methods and tools with code and data during the workshop to explore what they do and how they might work in a research workflow. Participants can compare benefits of new practices and ask questions to help clarify which would provide them the most value to adopt.
Open source infrastructure has paved the way for mission-aligned research stakeholders to …
Open source infrastructure has paved the way for mission-aligned research stakeholders to create a united vision of interoperable tools and services that accelerate scholarly communication, fill technology gaps, converge solutions, and enable access and discoverability.
Hear from a panel of research groups that have taken advantage of interoperable infrastructure to leverage more robust workflows to support rigorous, reproducible research. We also discuss the steps stakeholders and institutions can take to integrate OSF’s open API with existing services to establish streamlined researcher workflows.
View the slides from this presentation by visiting osf.io/ux7ed.
Library Carpentry lesson: An introduction to Git. What We Will Try to …
Library Carpentry lesson: An introduction to Git. What We Will Try to Do Begin to understand and use Git/GitHub. You will not be an expert by the end of the class. You will probably not even feel very comfortable using Git. This is okay. We want to make a start but, as with any skill, using Git takes practice. Be Excellent to Each Other If you spot someone in the class who is struggling with something and you think you know how to help, please give them a hand. Try not to do the task for them: instead explain the steps they need to take and what these steps will achieve. Be Patient With The Instructor and Yourself This is a big group, with different levels of knowledge, different computer systems. This isn’t your instructor’s full-time job (though if someone wants to pay them to play with computers all day they’d probably accept). They will do their best to make this session useful. This is your session. If you feel we are going too fast, then please put up a pink sticky. We can decide as a group what to cover.
This Library Carpentry lesson introduces librarians and others to working with data. …
This Library Carpentry lesson introduces librarians and others to working with data. This Library Carpentry lesson introduces people with library- and information-related roles to working with data using regular expressions. The lesson provides background on the regular expression language and how it can be used to match and extract text and to clean data.
Library Carpentry lesson: an introduction to OpenRefine for Librarians This Library Carpentry …
Library Carpentry lesson: an introduction to OpenRefine for Librarians This Library Carpentry lesson introduces people working in library- and information-related roles to working with data in OpenRefine. At the conclusion of the lesson you will understand what the OpenRefine software does and how to use the OpenRefine software to work with data files.
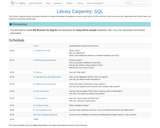
Library Carpentry, an introduction to SQL for Librarians This Library Carpentry lesson …
Library Carpentry, an introduction to SQL for Librarians This Library Carpentry lesson introduces librarians to relational database management system using SQLite. At the conclusion of the lesson you will: understand what SQLite does; use SQLite to summarise and link data.
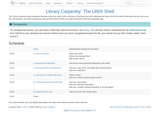
Library Carpentry lesson to learn how to use the Shell. This Library …
Library Carpentry lesson to learn how to use the Shell. This Library Carpentry lesson introduces librarians to the Unix Shell. At the conclusion of the lesson you will: understand the basics of the Unix shell; understand why and how to use the command line; use shell commands to work with directories and files; use shell commands to find and manipulate data.
Join us for a 30 minute guest webinar by Brandon Butler, Director …
Join us for a 30 minute guest webinar by Brandon Butler, Director of Information Policy at the University of Virginia. This webinar will introduce questions to think about when picking a license for your research. You can signal which license you pick using the License Picker on the Open Science Framework (OSF; https://osf.io). The OSF is a free, open source web application built to help researchers manage their workflows. The OSF is part collaboration tool, part version control software, and part data archive. The OSF connects to popular tools researchers already use, like Dropbox, Box, Github, Mendeley, and now is integrated with JASP, to streamline workflows and increase efficiency.
Background We explore whether the number of null results in large National …
Background We explore whether the number of null results in large National Heart Lung, and Blood Institute (NHLBI) funded trials has increased over time. Methods We identified all large NHLBI supported RCTs between 1970 and 2012 evaluating drugs or dietary supplements for the treatment or prevention of cardiovascular disease. Trials were included if direct costs >$500,000/year, participants were adult humans, and the primary outcome was cardiovascular risk, disease or death. The 55 trials meeting these criteria were coded for whether they were published prior to or after the year 2000, whether they registered in clinicaltrials.gov prior to publication, used active or placebo comparator, and whether or not the trial had industry co-sponsorship. We tabulated whether the study reported a positive, negative, or null result on the primary outcome variable and for total mortality. Results 17 of 30 studies (57%) published prior to 2000 showed a significant benefit of intervention on the primary outcome in comparison to only 2 among the 25 (8%) trials published after 2000 (χ2=12.2,df= 1, p=0.0005). There has been no change in the proportion of trials that compared treatment to placebo versus active comparator. Industry co-sponsorship was unrelated to the probability of reporting a significant benefit. Pre-registration in clinical trials.gov was strongly associated with the trend toward null findings. Conclusions The number NHLBI trials reporting positive results declined after the year 2000. Prospective declaration of outcomes in RCTs, and the adoption of transparent reporting standards, as required by clinicaltrials.gov, may have contributed to the trend toward null findings.
Is there a difference in citation rates between articles that were published …
Is there a difference in citation rates between articles that were published with links to data and articles that were not? Besides being interesting from a purely academic point of view, this question is also highly relevant for the process of furthering science. Data sharing not only helps the process of verification of claims, but also the discovery of new findings in archival data. However, linking to data still is a far cry away from being a "practice", especially where it comes to authors providing these links during the writing and submission process. You need to have both a willingness and a publication mechanism in order to create such a practice. Showing that articles with links to data get higher citation rates might increase the willingness of scientists to take the extra steps of linking data sources to their publications. In this presentation we will show this is indeed the case: articles with links to data result in higher citation rates than articles without such links. The ADS is funded by NASA Grant NNX09AB39G.
This recorded webinar features insights from international panelists currently nurturing culture change …
This recorded webinar features insights from international panelists currently nurturing culture change in research among their local communities.Representat...
No restrictions on your remixing, redistributing, or making derivative works. Give credit to the author, as required.
Your remixing, redistributing, or making derivatives works comes with some restrictions, including how it is shared.
Your redistributing comes with some restrictions. Do not remix or make derivative works.
Most restrictive license type. Prohibits most uses, sharing, and any changes.
Copyrighted materials, available under Fair Use and the TEACH Act for US-based educators, or other custom arrangements. Go to the resource provider to see their individual restrictions.